
Principles of machine learning frame how we define problems, choose algorithms, and evaluate results. This guide keeps the ideas practical with clear steps and examples.
Machine learning allows computers to learn from data without explicit programming. Unlike traditional programming, where developers write rules manually, machine learning allows machines to improve their performance over time through experience. To understand this concept, imagine teaching a child how to recognize different shapes and colors. At first, they may struggle, but with enough examples, feedback, and corrections, they gradually get better. Similarly, machine learning models process data, identify patterns, and refine their accuracy over time.
Machine learning fundamentals cover how models learn patterns from data to make predictions or decisions without being explicitly programmed. You gather and clean the data, split it into training/validation/test sets, and transform the raw inputs into features that the model can use. The model’s goal is to minimize a loss function (e.g., MSE for regression, cross-entropy for classification) while generalizing to new data. Standard evaluation metrics include accuracy, precision/recall, F1, and ROC-AUC for classification and MAE/MSE/RMSE for regression. Reproducibility, data quality, and a clear problem definition are just as crucial as algorithm choice.
Principles of machine learning: Supervised vs unsupervised learning
Supervised vs unsupervised learning distinguishes between tasks with labeled outcomes and those without. In supervised learning, each input has a known target (e.g., house price or spam/not spam), and models such as linear regression, logistic regression, random forests, gradient boosting, and neural networks learn to predict that target. In unsupervised learning, labels are absent; the goal is to discover structure—through clustering (k-means, hierarchical, DBSCAN) and dimensionality reduction (PCA, t-SNE, UMAP)—to reveal patterns. Many real-world projects combine both approaches: use unsupervised steps to engineer features, then train a supervised model to optimize the business objective.
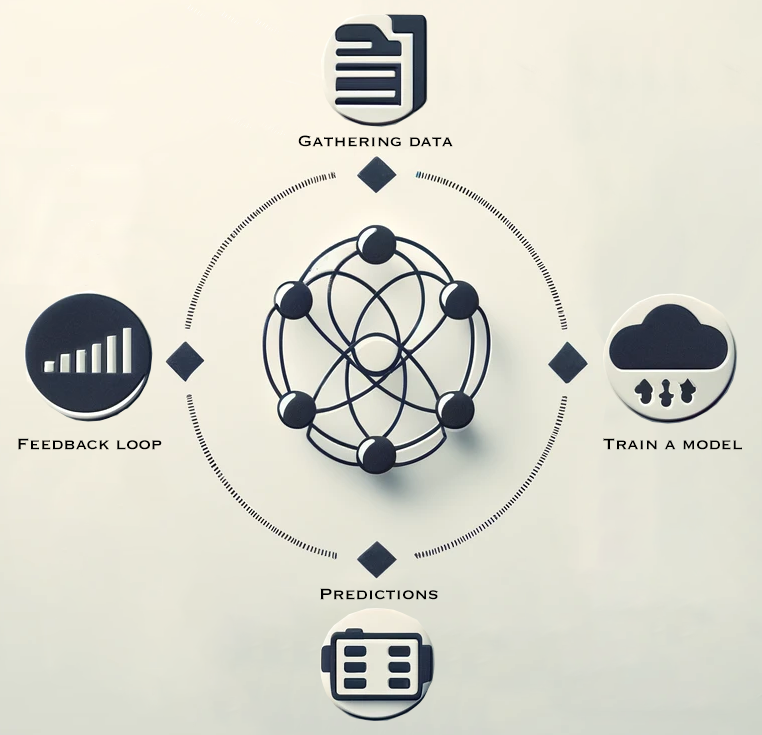
Concept of Machine Learning Through a Child Learning Example
One of the best ways to explain machine learning is by drawing an analogy to how a child learns. Let’s break this down into four key steps:
- Gathering Data
- Training a Model
- Making Predictions
- Feedback Loop
Each of these steps is key to creating a successful machine learning algorithm, just as they are essential in a child’s learning journey.
📌 Step 1: Gathering data
Before a child can learn to recognize shapes, they first need exposure to different examples. In machine learning, this stage involves collecting and labeling data.
For example, imagine you show a child a green circle and say, “This is a green circle.” You then introduce them to a red triangle, blue square, and so on. By repeatedly seeing different examples, the child starts associating colors and shapes with their names.
Similarly, in machine learning:
- A dataset is collected: This could be images of shapes, medical records, or customer preferences.
- Labels are assigned: For supervised learning, each piece of data is labeled, just as the child learns that a “circle” is different from a “triangle.”
- Familiarization occurs: The system (or child) starts recognizing patterns in the data.
📌 Step 2: Training a model
Now that the child has seen many examples, they need a way to process and remember them. This is the learning phase.
The more they practice, the better they get.
- The child sees more shapes without labels and is asked to guess which category they belong to.
- If they guess correctly, they reinforce their understanding.
- If they guess incorrectly, they receive feedback.The more they practice, the better they get.
Similarly, in machine learning:
- A model is fed labeled data.
- It tries to identify patterns.
- Through repeated exposure, the model improves its accuracy.
📌 Step 3: Making Predictions
Once the child has seen enough examples, they start making educated guesses.
- If they see a yellow triangle, they might say, “This is a triangle.”
- At first, they may make mistakes, but over time, their accuracy improves.
Likewise, a machine learning model:
- Takes new, unseen data.
- Uses previously learned patterns to make predictions.
- It improves over time as it processes more data.
📌 Step 4: The Feedback loop
No learning process is perfect. Mistakes happen, but they are crucial for improvement.
For a child:
- If they misidentify a blue square as a triangle, a teacher corrects them.
- This correction helps them refine their understanding.
For a machine learning algorithm:
The model continuously improves through this process.
- Predictions are compared against actual results.
- If the prediction is wrong, an adjustment is made.
- The model continuously improves through this process.